
انویدیا با معرفی خانواده Nemotron-3 در مقیاسهای نانو، سوپر و اولترا، مبتنی بر معماری ترکیبی پنهان از متخصصان (MoE) و آموزش کمدقت NVFP4، جهشی چشمگیر در کارایی، مقیاسپذیری و کاهش هزینه استنتاج مدلهای باز هوش مصنوعی چندعاملی ایجاد کرده است.
به گزارش سرویس هوشمصنوعی مگ دید، شرکت انویدیا، پیشرو در فناوریهای هوش مصنوعی، امروز از جدیدترین خانواده مدلهای هوش مصنوعی باز خود، تحت عنوان “Nemotron-3” رونمایی کرد. این خانواده شامل سه مدل با اندازههای متفاوت (نانو، سوپر و اولترا) است که با هدف تسریع توسعه و استقرار هوش مصنوعی عامل شفاف، کارآمد و تخصصی در صنایع مختلف طراحی شدهاند. مدلهای Nemotron-3، با معرفی یک معماری پیشگامانه “ترکیبی پنهان از متخصصان (MoE)”، به توسعهدهندگان در ساخت سیستمهای چندعاملی قابل اعتماد در مقیاس بزرگ کمک میکنند.
معرفی Nemotron-3، در راستای تلاشهای گستردهتر انویدیا برای پشتیبانی از هوش مصنوعی مستقل و همکاران شفاف در سراسر جهان است. سازمانهای متعددی از اروپا تا کره جنوبی، این مدلهای باز، شفاف و کارآمد را برای ساخت سیستمهای هوش مصنوعی منطبق با دادهها، مقررات و ارزشهای خاص خود به کار میگیرند.
پذیرندگان اولیه شامل شرکتهای بزرگی نظیر اکسنچر، کادنس، کروداسترایک، دیلویت، EY، اوراکل، پالانتیر، پرپلکسیتی، سرویسناو، زیمنس و زوم هستند که مدلهای Nemotron را برای تقویت گردشهای کاری هوش مصنوعی در حوزههایی مانند تولید، امنیت سایبری، توسعه نرمافزار، رسانه و ارتباطات یکپارچه میکنند. این مدلها به استارتاپها نیز امکان میدهند تا عوامل هوش مصنوعی را سریعتر بسازند و نوآوری را از نمونه اولیه تا استقرار سازمانی تسریع بخشند.

خانواده Nemotron-3 MoE در سه اندازه طراحی شده است:
- Nemotron-3 Nano (نانو): این مدل کوچک ۳۰ میلیارد پارامتری با ۳ میلیارد فعال، برای کارهای هدفمند و بسیار کارآمد طراحی شده است.
- Nemotron-3 Super (سوپر): این مدل با تقریباً ۱۰۰ میلیارد پارامتر و ۱۰ میلیارد فعال، یک مدل استدلالی با دقت بالا برای کاربردهای چندعاملی است.
- Nemotron-3 Ultra (اولترا): این مدل بزرگ با حدود ۵۰۰ میلیارد پارامتر و ۵۰ میلیارد فعال، به عنوان یک موتور استدلالی قدرتمند برای کاربردهای پیچیده هوش مصنوعی عمل میکند.
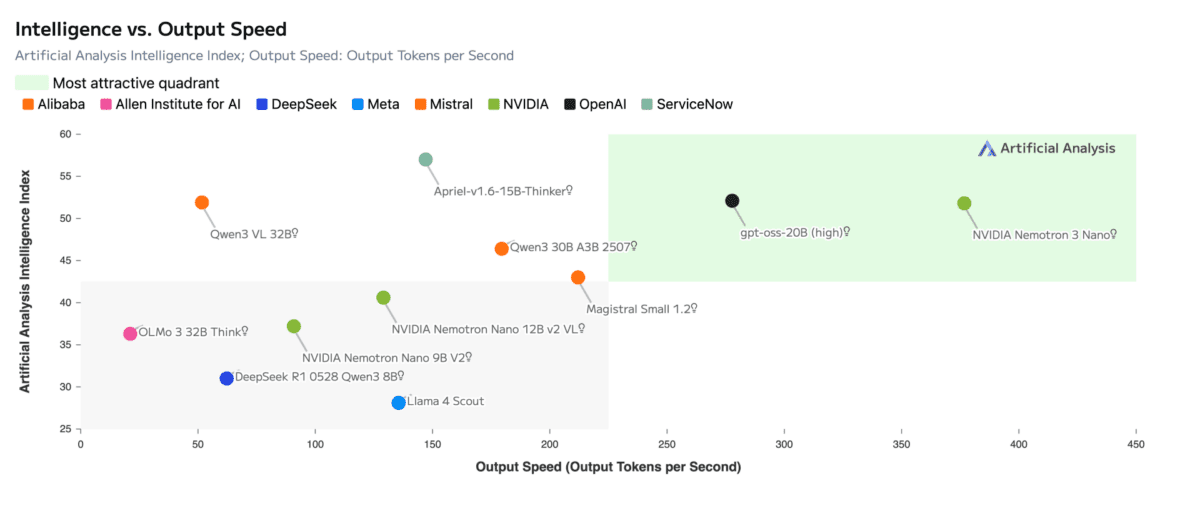
مدل Nemotron-3 Nano که هماکنون در دسترس است، مقرونبهصرفهترین مدل از نظر هزینه محاسباتی محسوب میشود. این مدل برای وظایف هدفمندی نظیر رفع اشکال نرمافزار، خلاصهسازی محتوا، دستیاران هوش مصنوعی و بازیابی اطلاعات با هزینههای استنتاج پایین بهینهسازی شده است. Nemotron-3 Nano از یک معماری MoE هیبریدی منحصربهفرد استفاده میکند که بهبودهای قابل توجهی در کارایی و مقیاسپذیری ارائه میدهد.
این طراحی، توان عملیاتی توکن را تا ۴ برابر در مقایسه با Nemotron-2 Nano افزایش داده و تولید توکن استدلالی را تا ۶۰ درصد کاهش میدهد که منجر به کاهش چشمگیر هزینههای استنتاج میشود. همچنین، با پنجره متنی یک میلیون توکنی، Nemotron-3 Nano قادر به حفظ اطلاعات بیشتری است که آن را در اتصال اطلاعات در طول وظایف طولانی و چند مرحلهای دقیقتر و توانمندتر میسازد. Artificial Analysis، یک سازمان مستقل ارزیابی هوش مصنوعی، این مدل را به عنوان بازترین و کارآمدترین مدل در میان هماندازههای خود، با دقت پیشرو، رتبهبندی کرده است.
Nemotron-3 Super در کاربردهایی که به همکاری چندین عامل برای انجام وظایف پیچیده با تاخیر کم نیاز دارند، عالی عمل میکند. در همین حال، Nemotron-3 Ultra به عنوان یک موتور استدلالی پیشرفته برای گردشهای کاری هوش مصنوعی که مستلزم تحقیقات عمیق و برنامهریزی استراتژیک هستند، عمل خواهد کرد.
به نقل از wccftech، مدلهای Nemotron-3 Super و Ultra از فرمت آموزشی فوقالعاده کارآمد ۴ بیتیNVFP4 انویدیا بر روی معماری NVIDIA Blackwell استفاده میکنند. این فرمت، نیازهای حافظه را به طور قابل توجهی کاهش داده و فرآیند آموزش را تسریع میبخشد.
این کارایی، امکان آموزش مدلهای بزرگتر را بر روی زیرساختهای موجود بدون به خطر انداختن دقت در مقایسه با فرمتهای با دقت بالاتر فراهم میکند. توسعهدهندگان با استفاده از خانواده Nemotron-3 میتوانند مدل باز مناسب برای بارهای کاری خاص خود را انتخاب کرده و مقیاسپذیری از دهها تا صدها عامل را تجربه کنند. آنها همچنین از استدلال سریعتر و دقیقتر با افق دید بلند برای گردشهای کاری پیچیده بهرهمند خواهند شد.
Nemotron-3 Nano هماکنون در Hugging Face و از طریق ارائهدهندگان خدمات استنتاجی مانند Baseten، Deepinfra، Fireworks، FriendliAI، OpenRouter و Together AI در دسترس است. این مدل همچنین در پلتفرمهای زیرساخت داده و هوش مصنوعی سازمانی از جمله Couchbase، DataRobot، H2O.ai، JFrog، Lambda و UiPath ارائه میشود.
به زودی، Nemotron-3 Nano برای مشتریان در ابرهای عمومی از طریق Amazon Bedrock (بدون سرور)، گوگل کلود، کورویو، نبیوس، اناسکیل و یوتا نیز پشتیبانی خواهد شد. این مدل به عنوان یک میکروسرویس NVIDIA NIM™ نیز برای استقرار امن و مقیاسپذیر در هر نقطه از زیرساختهای شتابدهنده انویدیا برای حداکثر حریم خصوصی و کنترل در دسترس است. انتظار میرود مدلهای Nemotron-3 Super و Ultra انویدیا در نیمه اول سال ۲۰۲۶ در دسترس قرار گیرند.